Postgres Hibernator: Reduce Planned Database Down Times
TL;DR: Reduce planned database down times by about 97%, by using Postgres Hibernator.
DBAs are often faced with the task of performing some maintenance on their database server(s) which requires shutting down the database. The maintenance may involve anything from a database minor-version upgrade, to a hardware upgrade. One ugly side-effect of restarting the database server/service is that all the data currently in database server’s memory will be all lost, which was painstakingly fetched from disk and put there in response to application queries over time. And this data will have to be rebuilt as applications start querying database again. The query response times will be very high until all the “hot” data is fetched from disk and put back in memory again.
People employ a few tricks to get around this ugly truth, which range from running a select * from app_table;, to dd if=table_file ..., to using specialized utilities like pgfincore to prefetch data files into OS cache. Wouldn’t it be ideal if the database itself could save and restore its memory contents across restarts!
The Postgres Hibernator extension for Postgres performs the automatic save and restore of database buffers, integrated with database shutdown and startup, hence reducing the durations of database maintenance windows, in effect increasing the uptime of your applications.
Postgres Hibernator automatically saves the list of shared buffers to the disk on database shutdown, and automatically restores the buffers on database startup. This acts pretty much like your Operating System’s hibernate feature, except, instead of saving the contents of the memory to disk, Postgres Hibernator saves just a list of block identifiers. And it uses that list after startup to restore the blocks from data directory into Postgres’ shared buffers.
As explained in my earlier post, this extension is a set-it-and-forget-it solution, so, to get the benefits of this extension there’s not much a DBA has to do, except install it.
Ideal database installations that would benefit from this extension would be the ones with a high cache-hit ratio. With Postgres Hibernator enabled, your database would start cranking pre-maintenance TPS (Transactions Per Second) within first couple of minutes after a restart.
As can be seen in the chart below, the database ramp-up time drops dramatically when Postgres Hibernator is enabled. The sooner the database TPS can reach the steady state, the faster your applications can start performing at full throttle.
The ramp-up time is even shorter if you wait for the Postgres Hibernator processes to end, before starting your applications.
Sample Runs
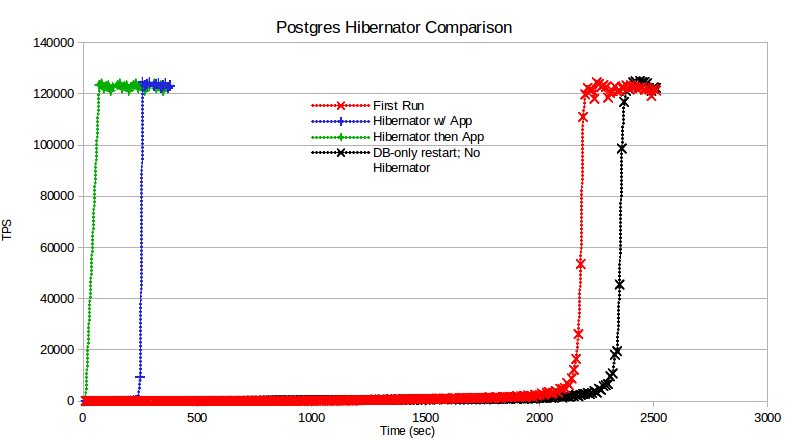
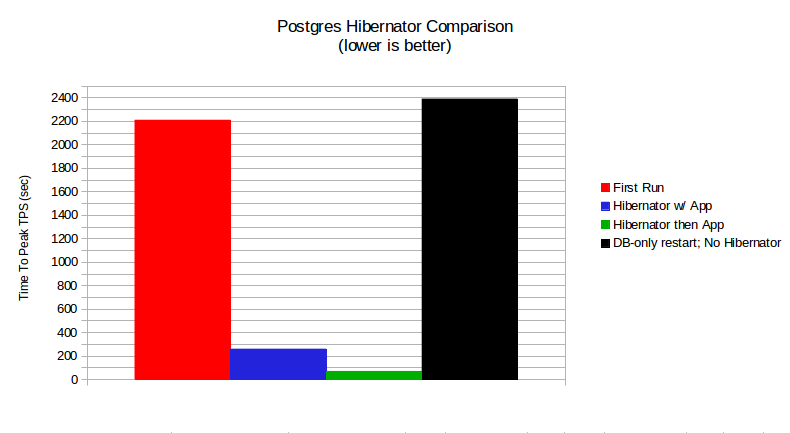
As is quite evident, waiting for Postgres Hibernator to finish loading the data blocks before starting the application yeilds a 97% impprovement in database ramp-up time (2300 seconds to get to 122k TPS without Postgres Hibernator vs. 70 seconds).
Details
Please note that this is not a real benchmark, just something I developed to showcase this extension at its sweet spot.
The full source of this mini benchmark is available with the source code of the Postgres Hibernator, at its Git repo.
Hardware: MacBook Pro 9,1
OS Distribution: Ubuntu 12.04 Desktop
OS Kernel: Linux 3.11.0-19-generic
RAM: 8 GB
Physical CPU: 1
CPU Count: 4
Core Count: 8
pgbench scale: 260 (~ 4 GB database)
Before every test run, except the last (‘DB-only restart; No Hibernator’), the Linux OS caches are dropped to simulate an OS restart.
In ‘First Run’, the Postgres Hibernator is enabled, but since this is the first ever run of the database, Postgres Hibernator doesn’t kick in until shutdown, to save the buffer list.
In ‘Hibernator w/ App’, the application (pgbench) is started right after database restart. The Postgres Hibernator is restoring the data blocks to shared buffers while the application is also querying the database.
In the ‘App after Hibernator’ case, the application is started after the Postgres Hibernator has finished reading database blocks. This took 70 seconds for reading the ~4 GB database.
In ‘DB-only restart; No Hibernator` run, the OS caches are not dropped, but just the database service is restarted. This simulates database minor version upgrades, etc.
It’s interesting to monitor the bi column in vmstat 10 output, while these tests are running. In ‘First Run’ and ‘DB-only restart’ cases this column’s values stayed between 2000 and 5000 until all data was in shared buffers, and then it dropped to zero (meaning that all data has been read from disk into shared buffers). In ‘Hibernator w/ app’ case, this column’s value ranges from 15,000 to 65,000, with an average around 25,000. it demonstrates that Postgres Hibernator’s Block Reader process is aggressively reading the blocks from data directory into the shared buffers, but apparently not fast enough because the applicaion’s queries are causing random reads from disk, which interfere with the sequential scans that Postgres Hibernator is trying to perform.
And finally, in ‘App after Hibernator’ case, this column consistently shows values between 60,000 and 65,000, implying that in absence of simultaneous application load, the Block Reader can read data into shared buffers much faster.